
Die Wirtschaftsuniversität Wien hat zusammen mit dem Board Service Center die Rechnungswesenskompetenz von 13 führenden KI-Sprachmodellen getestet. Hierzu wurden den Modellen über 500 Fragen aus den Bereichen Rechnungswesen, Management Accounting und Steuerrecht gestellt. Die Ergebnisse bieten einige interessante Erkenntnisse.
Die Studie
Im Rahmen der Untersuchung wurden die folgenden KI-Sprachmodelle getestet:
Jedem Modell wurden dabei über 500 Fragen aus Universitätskursen und von professionellen Examina zur Beantwortung gegeben, wobei jede Frage dreimal gestellt wurde. Die Antwort, die am häufigsten vorkam, wurde als endgültige Antwort verwendet, um zufällige Schwankungen zu reduzieren.
Die Steuerrechtsfragen basierten dabei auf dem österreichischen Steuerrecht, während im Bereich des Rechnungswesens ein Mix aus nationalen und internationalen Rechnungslegungsstandards verwendet wurde.
Die Ergebnisse
Als Gesamtsieger wurde das OpenAI Modell GPT-5.5 gekürt. Die Auswertung zeigt aber, dass es bei diversen Aufgabengebieten zu großen Schwankungen kommt:
- So führt GPT-5.5 mit deutlichem Abstand in den Bereichen Financial Accounting (Rechnungswesen) und Tax (Steuer).
- Im Bereich des Management Accounting schneiden die Programme claude-opus-4-7, GPT-5.4, GPT-5.2 und claude-sonnet-4-6 dagegen besser ab.
Interessant ist auch ein Blick auf die Kosten. So wurden für GPT-5.5 Kosten im Wert von $ 0.0338 pro Aufgabe ermittelt. Bei DeepSeek-V3.2 schlugen dagegen nur $ 0.00030 zu Buche. Die Nutzung von DeepSeek-V3.2 verursacht somit nur 1% der Kosten im Vergleich zur Nutzung von GPT-5.5.
Im Bereich der Schnelligkeit der Antworten zeichnet sich besonders das Sprachmodell Mercury-2 aus. Zu beachten ist, dass dieses Modell aber auch am schlechtesten in der Qualität der Antworten abschneidet. Wobei sich auch hier ein Blick auf das Aufgabenfeld lohnt. So fallen die Ergebnisse von Mercury-2 schwach (weak) im Financial Accounting und schlecht (poor) im Bereich des Steuerrechts aus. Im Bereich des Management Accountings wird dieses Modell dagegen als stark (strong) gewertet.
Als Letztes ist noch auf den Bereich der Aufgabenart hinzuweisen:
- Bei der Aufgabenart „Berechnung“ (calculation) ist keines der Modelle besser als schlecht (poor) bewertet worden.
- Bei den Aufgabenarten „Gesetzesinterpretation“ (interpretation of law) und „Buchungssätze“ (journal entries) haben mehrere Modelle dagegen ein starkes (strong) Ergebnis geliefert.
Fazit
Die einzelnen Sprachmodelle unterscheiden sich erheblich in der Qualität, den Kosten und der Geschwindigkeit der Antworten. Dabei ist zu beachten, dass die verschiedenen Modelle ihre individuellen Stärken haben. So schneiden die Modelle GPT-5.5 und Mistral-Large-3 im Bereich des Management Accountings in etwa gleich ab, wobei die Nutzung von Mistral-Large-3 um die Hälfte günstiger ist. Zu berücksichtigen ist auch, dass keines der Sprachmodelle verlässliche Berechnungen vornehmen kann. Es sind und bleiben Sprachmodelle, keine Rechenoperatoren.
Dass ChatGPT in steuerlichen Sachverhalten schon recht versiert ist, zeigt der folgende Prompt. Danach hat ChatGPT die Problematik der Aufgabenstellung von Anfang an richtig erkannt: 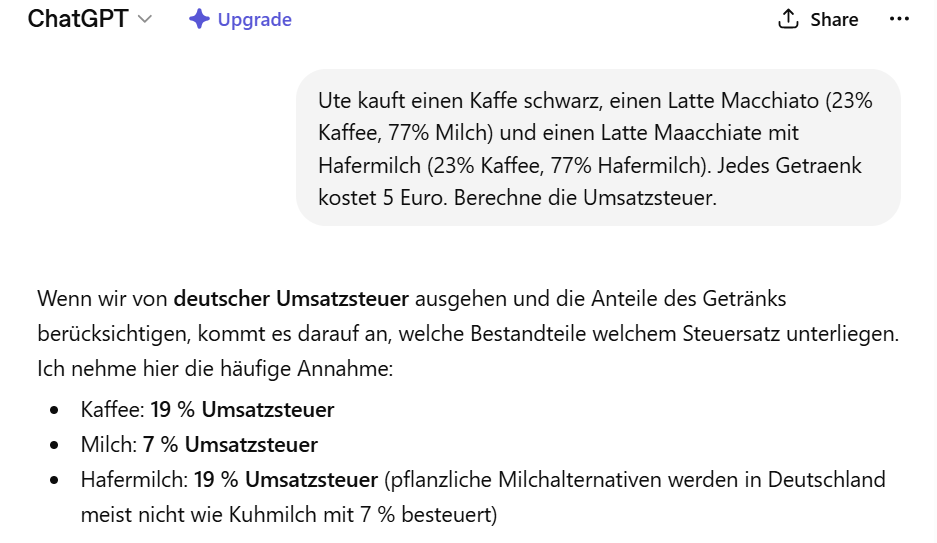

|
Christian Thurow, Dipl.-Betriebsw. (BA), Senior Risk Manager, London (E-Mail: c.thurow@thurow.co.uk)
BC 7/2026
BC20260704